Use one of the following to add a Phoenix Model object to a Workflow:
Right-click menu for a Workflow object: New > Phoenix Modeling > Phoenix Model.
Main menu: Insert > Phoenix Modeling > Phoenix Model.
Right-click menu for a worksheet: Send To > Phoenix Modeling > Phoenix Model.
Note:To view the object in its own window, select it in the Object Browser and double-click it or press ENTER. All instructions for setting up and execution are the same whether the object is viewed in its own window or in Phoenix view.
This section contains information on the following topics:
See “Phoenix Model output” for lists of result worksheets, plots, and text files.
Use the Main Mappings panel to identify how input variables are used in a Phoenix Model object. Required input is highlighted orange in the interface.
The dataset that is mapped to the main Mappings panel must contain time and concentration data, and sort variables to identify individual profiles.
Note:Context associations change depending on the selected Phoenix Model model and on options selected in the Structure tab and Input Options tab.
Intravenous PK model
•None: Data types mapped to this context are not included in any analysis or output.
•Sort: Up to 5 additional study variables used to sort the output. A separate analysis is performed for each unique combination of sort variable values.
•ID: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and treatment in a crossover study. Only available in Population modeling. Do not use sort values when pooling data. See “Pooled data” for more information.
•A1: The IV bolus dose amount. Used if Intravenous is selected in the Absorption menu.
•Aa: The extravascular dose amount. Used if Extravascular is selected in the Absorption menu.
•Time: The relative or nominal dosing times used in a study.
•CObs: The continuous observations of drug concentration in the blood.
Emax or Linear model
•None: Data types mapped to this context are not included in any analysis or output.
•Sort: Up to 5 additional study variables used to sort the output. A separate analysis is performed for each unique combination of sort variable values.
•ID: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and treatment in a crossover study. Only available in Population modeling. Do not use sort values when pooling data. See “Pooled data” for more information.
•C: The input concentration used to determine the output effect.
•EObs: The observed drug effect.
Note:Linked PK, Emax, Indirect, and Linear models all use some combination of the contexts listed above.
Extra input options
•A1 Rate/A1 Duration: The rate/duration of drug delivery in an IV infusion.
•Aa Rate/Aa Duration: The rate/duration of drug delivery when using an extravascular delivery method.
•Date: Year, month, or day.
•Time: The relative or nominal dosing times used in a study.
•CObsBQL: Allows users to map a dataset to the Main Mappings panel that contains BQL values for the continuous observation values.
•A0Obs: Appears if Elim. Cpt. is checked. This is the observed amount of drug in the elimination compartment.
•MDV: Missing dependent variable.
•SteadyState: Used if the model reaches a steady state of dosing.
•ADDL: Used if additional identical doses are included in the primary dataset.
See “Main Mappings panel input data” and “Dosing input options” for additional details about the variables that appear in this panel.
The Model panel is utilized with the graphical building of models. It is not used for built-in models. However, it does show a graphical representation of a built-in model, if possible. In some cases, it is not possible to show a unique model diagram; for example, in the case of closed-form macro constant models.
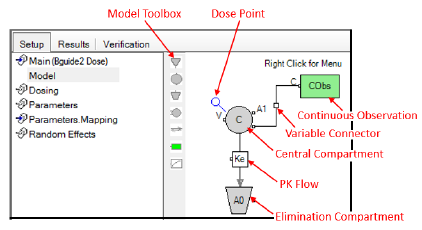
Dosing is only required for PK models.
•None: Data types mapped to this context are not included in any analysis or output.
•Sort: Up to 5 additional study variables used to sort the output. A separate analysis is performed for each unique combination of sort variable values.
•ID: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and treatment in a crossover study. Only available in Population modeling. Do not use sort values when pooling data. See “Pooled data” for more information.
•A1: The amount of drug administered intravenously.
•A1 Rate/A1 Duration: The rate/duration of infusion for drugs administered intravenously.
•Aa: The amount of drug administered extravascularly.
•Aa Rate/Aa Duration: The rate/duration of infusion for drugs administered extravascularly.
•C: The input concentration used to determine the output effect. Used with Emax, Indirect, and Linear models.
•Time: The time of dose administration.
Selecting different input options in the Input Options tab adds the following extra columns in the Dosing panel for each model.
•MDV?: Used if the dosing data contains a missing data value column.
•Steady State: Used if the model is steady state.
•ADDL: User-specified additional dosing items.
•Date?: Used if the dosing data contains a column with dates.
Note:If an internal worksheet is used, input for all values of the sort variables is required.
An internal dosing worksheet should be rebuilt when changing a model from individual to population, or vice versa, and changing between Sort and ID mapping. Otherwise it can cause a verification error upon execution.
See “Main Mappings panel input data” and “Dosing input options” for additional details about the variables that appear in this panel.
The Parameters panel allows users to map a worksheet with initial, lower, and upper parameter values. This is a convenient way to use results from another computation to set initial estimates for a model without having to manually enter values.
Parameter value options can also be specified in the Fixed Effects tab which is located under the Parameters tab.
•None: Data types mapped to this context are not included in any analysis or output.
•Sort: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and gender. A separate analysis is done for each unique combination of sort variable values.
•Parameter: The parameters used in the structural model.
•Initial: The initial value for each parameter.
•Lower: The lower limit value for each parameter.
•Upper: The upper limit value for each parameter.
Use the Rebuild button to reset the internal worksheet to its default state.
Note:If an internal worksheet is used, input for all values of the sort variables is required
If an external worksheet is mapped to the Parameters panel, and the parameter names in the worksheet do not match the parameter names in the Phoenix model, the Parameters.Mapping panel can be used to match external parameter names with internal ones. If the parameter names match or no external parameters worksheet is used, then there is no need to use the Parameters.Mapping panel.
-
Map an external worksheet with parameters and initial estimates to the Parameters panel.
-
Select the Parameters.Mapping panel.
The Use Internal Worksheet checkbox is selected by default. -
Click Rebuild to update the internal Parameters.Mapping worksheet.
-
Beside each external parameter name in the Names dialog, select the checkbox underneath the corresponding internal parameter name.
-
Click OK to accept the matched parameter names and close the dialog.
Note:If the Parameters.Mapping panel is not used when a worksheet is specified for initial estimates, the values shown in the Parameters tab are used.
The Random Effects panel allows users to map a worksheet with sorting and ID values. This is a convenient way to use results from another computation to set random effects values for a model without having to manually enter values.
Random Effects value options can also be specified in the Random Effects tab which is located under the Parameters tab.
•None: Data types mapped to this context are not included in any analysis or output.
•Sort: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and gender. A separate analysis is done for each unique combination of sort variable values.
•ID: Up to 5 categorical variable(s) identifying individual data profiles, such as subject ID and treatment in a crossover study. Only available in Population modeling.
Use the Rebuild button to reset the internal worksheet to its default state.
Do not use sort values when pooling data. See “Pooled data” for more information.
Note:If an internal worksheet is used, input for all values of the sort variables is required
