The Linear Mixed Effects operational object (LinMix) is a statistical analysis system for analysis of variance for crossover and parallel studies, including unbalanced designs. It can analyze regression and covariance models, and can calculate both sequential and partial tests. LinMix is discussed in the following sections.
Use one of the following to add the object to a Workflow:
Right-click menu for a Workflow object: New > Computation Tools > Linear Mixed Effects.
Main menu: Insert > Computation Tools > Linear Mixed Effects.
Right-click menu for a worksheet: Send To > Computation Tools > Linear Mixed Effects.
Note:To view the object in its own window, select it in the Object Browser and double-click it or press ENTER. All instructions for setting up and execution are the same whether the object is viewed in its own window or in Phoenix view.
User interface description
Results
General linear mixed effects model
Linear mixed effects computations
Linear mixed effects model examples
Main Mappings panel
Fixed Effects tab
Variance Structure tab
Random 1 and Repeated tabs
Contrasts tab
Contrast # 1 tab
Estimates tab
Estimate # 1 tab
Least Squares Means tab
General Options tab
Use the Main Mappings panel to identify how input variables are used in a linear mixed effects model. A separate analysis is performed for each profile. Required input is highlighted orange in the interface.
None: Data types mapped to this context are not included in any analysis or output.
Sort: Categorical variable(s) identifying individual data profiles, such as subject ID and treatment. A separate analysis is done for each unique combination of sort variable values. If a sort variable has missing values, then the analysis is performed for the missing level and MISSING is printed as the sort variable value.
Classification: Classification variables or factors that are categorical independent variables, such as formulation, treatment, and gender.
Regressors: Regressor variables or covariates that are continuous independent variables, such as temperature or body weight. The regressor variable can also be used to weight the dataset.
Dependent: The dependent variable, such as drug concentration, that provides the values used to fit the model.
For information on variable naming constraints and data limits, see “Data limits and constraints” in the Bioequivalence section.
Note:Be sure to finalize column names in your input data before sending the data to the Linear Mixed Effects object. Changing names after the object is set up can cause the execution to fail.
The Fixed Effects tab allows users to specify settings for study variables used in linear mixed effects model. The Model Specification field is used to categorize variables in a dataset for the linear mixed effects model. For more on fixed effects in the linear mixed effects model, see “Fixed effects”.
-
Drag variables from the Classification and the Regressors/Covariates boxes to the Model Specification field and click the operator buttons to build the model or type the names and operators directly in the field.
+ addition,
* multiplication,
( ) parentheses for indicating nested variables in the model
Below are some guidelines for using parentheses:
•Parentheses in the model specification represent nesting of model terms.
•Seq+Subject(Seq)+Period+Treatment is a valid use of parentheses and indicates that Subject is nested within Seq.
•Drug+Disease+(Drug*Disease) is not a valid use of parentheses in the model specification.
-
Select a weight variable from the Regressors/Covariates box and drag it to the Weight Variable field.
To remove a weight variable, drag the variable from the Weight Variable field back to the Regressors/Covariates box.
The Regressors/Covariates box lists variables that are mapped to the Regressors context (in the Main Mappings panel). If a variable is used to weight the data then the variable is displayed in the Regressors/Covariates box. Below are some guidelines for using weight variables:
•The weights for each record must be included in a separate column in the dataset.
•Weight variables are used to compensate for observations having different variances.
•When a weight variable is specified, each row of data is multiplied by the square root of the corresponding weight.
•Weight variable values should be proportional to the reciprocals of the variances. Typically, the data are averages and weights are sample sizes associated with the averages.
•The Weight variable cannot be a classification variable. It must be declared as a regressor/covariate before it can be used as a weight variable. It can also be used in the model.
-
In the Dependent Variables Transformation menu, select one of three options:
None
Ln(x): Linear transformation
Log10(x): Logarithmic base 10 transformation
-
In the Fixed Effects Confidence Level box, type the level for the fixed effects model. The default value is 95%.
-
By default, the intercept term is included in the model (although it is not shown in the Model Specification field), check the No Intercept checkbox to remove the intercept term.
Removing the intercept term changes the parameterization of the classification variables. See “Construction of the X matrix” for more information. -
Use the Test Numerator and Test Denominator fields to specify an additional test of hypothesis in the case of a model with only fixed effects.
For this case, the default error term (denominator) is the residual error, so an alternate test can be requested by entering the fixed effects model terms to use for the numerator and denominator of the F-test. The terms entered must be in the fixed effects model and the random/repeated models must be empty for the test to be performed. (See “Tests of hypotheses” for additional information.)
The Variance Structure tab allows users to set random effects and the repeated specification for the linear mixed effects model. Users can also set traditional variance components and random coefficients.
Users can specify none, one, or multiple random effects. The random effects specify Z and the corresponding elements of G=Var(g). Users can specify only one repeated effect. The repeated effect specifies the R=Var(e).
For more on variance structures in the linear mixed effects model, see “Variance structure”.
-
Select a variable in the Classification Variables box and drag it to the Random 1 tab or type variable names in the fields.
-
Select a variable in the Regressors/Covariates box and drag the variable to the Random 1 tab or type variable names in the fields.
The Random 1 tab is used to add random effects to the model. The random effects are built using the classification variables, the regressors/covariates variables, and the operator buttons.
The Repeated tab is used to specify the R matrix in the mixed model. The Repeated tab is also used to specify covariance structures for repeated measurements on subjects. If no repeated statement is specified, R is assumed to be equal to s2I. The repeated effect must contain only classification variables.
Caution:The same variable cannot be used in both the fixed effects specification and the random effects specification unless it is used differently, such as part of a product. The same term (single variables, products, or nested variables) must not appear in both specifications.
-
Drag variables from the boxes on the left to the fields in the tab and click the operator buttons to build the model or type the names and operators directly in the fields.
+ addition (not available in the Repeated tab or when specifying the variance blocking or group variables),
* multiplication,
( ) parentheses for indicating nested variables in the model.
This Variance Blocking Variables (Subject) field is optional and, if specified, must be a classification model term built from items in the Classification Variables box. This field is used to identify the subjects in a dataset. Complete independence is assumed among subjects, so the subject variable produces a block diagonal structure with identical blocks.
This Group field is also optional and, if specified, must be a classification model term built from items in the Classification Variables box. It defines an effect specifying heterogeneity in the covariance structure. All observations having the same level of the group effect have the same covariance parameters. Each new level of the group effect produces a new set of covariance parameters with the same structure as the original group.
-
(Random 1 tab only) Check the Random Intercept checkbox to include a random intercept.
This setting is commonly used when a subject is specified in the Variance Blocking Variables (Subject) field. The default setting is no random intercept. -
If the model contains random effects, a covariance structure type must be selected from the Type menu.
If Banded Unstructured (b), Banded No-Diagonal Factor Analytic (f), or Banded Toeplitz (b) is selected, type the number of bands in the Number of bands(b) field (default is 2).
The number of factors or bands corresponds to the dimension parameter. For some covariance structure types this is the number of bands and for others it is the number of factors.
For explanations of covariance structure types, see “Covariance structure types in the Linear Mixed Effects object”.
-
Click Add Random to add additional variance models.
-
Click Delete Random to delete a variance model.
The Contrasts tab provides a mechanism for creating custom hypothesis tests. For example, users can compare different treatments or treatment combinations to see if the mean values are the same. Contrasts can only be computed using the fixed effect model terms set in the Model Specification field. For more on contrasts in the linear mixed effects model, see “Contrasts”.
The Fixed Effects Model Terms box lists all the fixed effect model terms specified in the Fixed Effects tab. Users can drag a term from the Fixed Effect Model Terms box to the Effect field to compute the contrasts for that term.
The conditions for using model terms as effect variables are:
-
If all values of the dependent variable are missing or excluded for an effect variable level, then that level of the effect variable is not used in the Contrast vector.
-
Effect variables can be either numeric or alphabetic, but they cannot be both. If a column contains both numeric and alphabetic data, the column cannot be used as an effect variable when building contrasts.
-
Interactions can be used as contrasts only if the interaction is a model term.
-
Nested terms can be used as contrasts only if the nested term is a model term.
-
Drag a model term from the Fixed Effect Model Terms box to the Effect field.
To remove a model term, use the pointer to drag a model term from the Effect field back to the Fixed Effects Model Terms box. -
In the Title field, type a title for the contrast. The title is displayed in the Contrasts and Contrasts Coefficients worksheets.
-
In the Coefficients column, type the coefficient value for each level of the model term in the contrast.
Caution:The coefficients for contrasts must sum to zero.
Add extra columns to enter multiple coefficients for each model term in the contrast.
-
In the Number of columns for contrast box, select the number of coefficient columns to use with each contrast (default is 1).
If multiple coefficient columns are selected, then Phoenix simultaneously tests the multiple linearly independent combinations of coefficients. -
To set the degrees of freedom, check the User specified degrees of freedom checkbox and type a value greater than one (1) in the field.
Caution:Only select the User specified degrees of freedom option if the Phoenix engine does not seem to use the appropriate choices for the degrees of freedom.
Note:The Univariate Confidence Intervals use an approximation for the t-value that is very accurate when the degrees of freedom value is at least five, but loses accuracy as the degrees of freedom value approaches one. The degrees of freedom are the number of observations minus the number of parameters being estimated (not counting parameters that are within the singularity tolerance, i.e., nearly completely correlated).
-
Check the Show coefficients of contrasts checkbox to display the actual coefficients used in the Contrasts Coefficients results worksheet.
-
In the Estimability Tolerance field, type a value for the zero vector.
The estimability tolerance value indicates the closeness of the zero vector before the Phoenix engine is used to make it estimable. The default value is 1E–05. Users do not typically need to change this value. -
Click Add Contrast to add another contrast.
Each contrast is tested independently of other contrasts. Users can enter up to 100 contrasts. -
Click Delete Contrast to delete a contrast.
The Estimates tab provides a mechanism for creating custom hypothesis tests. Estimates can only be computed using the fixed effect model terms set in the Model Specification field. Since the Estimates tab produces estimates instead of contrasts, the coefficients do not have to sum to zero and more than one model term can be added to the Effect field. The marginal interval is generated for each estimate.
For more on estimates in the linear mixed effects model, see “Estimates”.
The Fixed Effects Model Terms box lists all the fixed effect model terms specified in the Fixed Effects tab. Users can drag a term from the Fixed Effect Model Terms box to the Effect field to compute the estimates for that term. The conditions for using model terms as effect variables are:
•Interaction terms and nested terms can be used if they are used in the model.
•If the fixed effects model includes an intercept, which is the default setting, then the intercept can be used to produce an estimate.
•If the intercept term is used as an effect for an estimate it works like a regressor, which means only one coefficient value is used for the intercept.
-
Drag a model term from the Fixed Effect Model Terms box to the Effect field.
•Multiple model terms can be dragged from the Fixed Effect Model Terms box to the Effect field.
•To remove a model term, use the pointer to drag a model term from the Effect field back to the Fixed Effects Model Terms box.
-
In the Title field, type a title for the estimate. The title is displayed in the Estimates and Estimates Coefficients worksheets.
-
In the Coefficients column, type the coefficient value for each level of the model term in the estimate.
-
Select the Intercept Coefficient checkbox to include the intercept in the estimate.
-
In the Intercept Coefficient field, type the coefficient value for the intercept.
-
In the Confidence Level field, type the level percentage. The default level is 95%. Users do not typically need to change this value.
-
To set the degrees of freedom, check the User specified degrees of freedom checkbox and type a value greater than one (1) in the field.
Caution:Only select the User specified degrees of freedom option if the Phoenix engine does not seem to use the appropriate choices for the degrees of freedom.
-
Check the Show coefficients of estimates checkbox to display the actual coefficients used in the Estimates Coefficients results worksheet.
-
In the Estimability Tolerance field, type a value for the zero vector.
The estimability tolerance value indicates the closeness of the zero vector before the Phoenix engine is used to make it estimable. The default value is 1E–05. Users do not typically need to change this value. -
Click Add Estimate to add another contrast.
Each estimate is tested independently of other estimates. Users can enter up to 100 estimates. -
Click Delete Estimate to delete a contrast.
Least squares means are generalized least-squares means of the fixed effects. They are estimates of what the mean values would have been had the data been balanced, which means these are the means predicted by the ANOVA model. If a dataset is balanced, the least squares means will be identical to the raw, or observed, means. Least Squares Means can be computed for any classification model term.
For more on least squares means in the linear mixed effects model, see “Least squares means”.
-
Drag a model term from the Fixed Effect Model Classifiable Terms box to the Least Squares Means field.
To remove a model term, drag a model term from the Least Squares Means field back to the Fixed Effect Model Classifiable Terms box. -
In the Confidence Level field, type the level percentage. The default level is 95%. Users do not typically need to change this value.
-
To set the degrees of freedom, check the User specified degrees of freedom checkbox and type a value greater than one (1) in the User specified degrees of freedom field.
-
Check the Show coefficients of LSMs checkbox to display the actual coefficients used in the LSM Coefficients results worksheet.
-
In the Estimability Tolerance field, type a value for the zero vector.
The estimability tolerance value indicates the closeness of the zero vector before the Phoenix engine is used to make it estimable. The default value is 1E–05. Users do not typically need to change this value. -
Select the Compute pairwise differences of LSMs checkbox to display the differences of intervals and LSMs in the LSM Differences results worksheet.
This function tests h1 = h2.
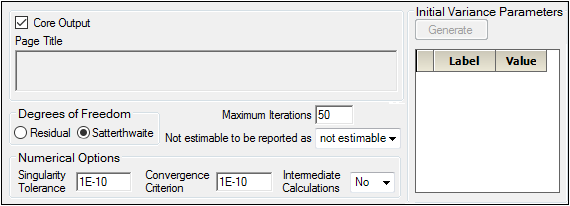
The General Options tab is used to set output and calculation options for a linear mixed effects model.
-
Check the Core Output checkbox to include the Core Output text file in the results.
-
In the Page Title field, type a title for the Core Output text file.
-
Choose the degrees of freedom calculation method:
Residual: The same as the calculation method used in a purely fixed effects model
Satterthwaite: The default setting and computes the df base on c2 approximation to distribution of variance.
-
In the Maximum Iterations field, type the number of maximum iterations. This is the number of iterations in the Newton fitting algorithm. The default setting is 50.
-
Use the Not estimable to be reported as menu to determine how output that is not estimable is represented.
•not estimable
•0 (zero)
-
In the Singularity Tolerance field, type the tolerance level. The columns in X and Z are eliminated if their norm is less than or equal to this number (default is1E–10).
-
In the Convergence Criterion field, type the criterion used to determine if the model has converged (default is 1E–10).
-
In the Intermediate Calculations menu, select whether or not to include the design matrix, reduced data matrix, asymptotic covariance matrix of variance parameters, Hessian, and final variance matrix in the Core Output text file.
Note:The Generate initial variance parameters option is available only if the model uses random effects.
-
In the Initial Variance Parameters group, click Generate to edit the initial variance parameters values.
-
Select a cell in the Value column and type a value for the parameter. The default value is 1.
If the values are not specified, then Phoenix uses the method of moments estimates.
To delete one or more of the parameters from the table:
•Highlight the row(s).
•Select Edit >> Delete from the menubar or click X in the main toolbar.
•Click the Selected Row(s) option button and click OK.
