Select the General link in the left list.
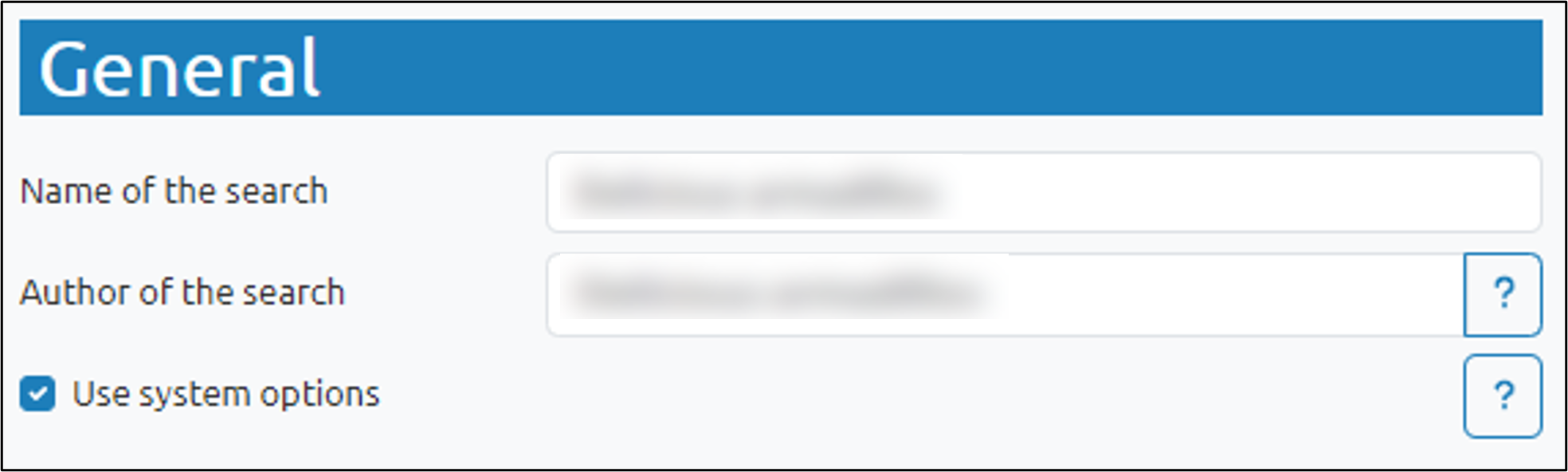
In the Name of the search field, enter a title with which to refer to this search. Acceptable characters include letters, digits, spaces, and the symbols ()[]#-_
In Author of the search field, enter the name of the person creating this search.
Check the Use system options box to override corresponding settings with those defined in a separate .json file that is specified on the “Darwin settings” preference page. This option removes the need to edit certain settings (e.g., the nmfe path or Rscript path) each time you change environments (GA GP RF GBRT PSO EX).
Performance options
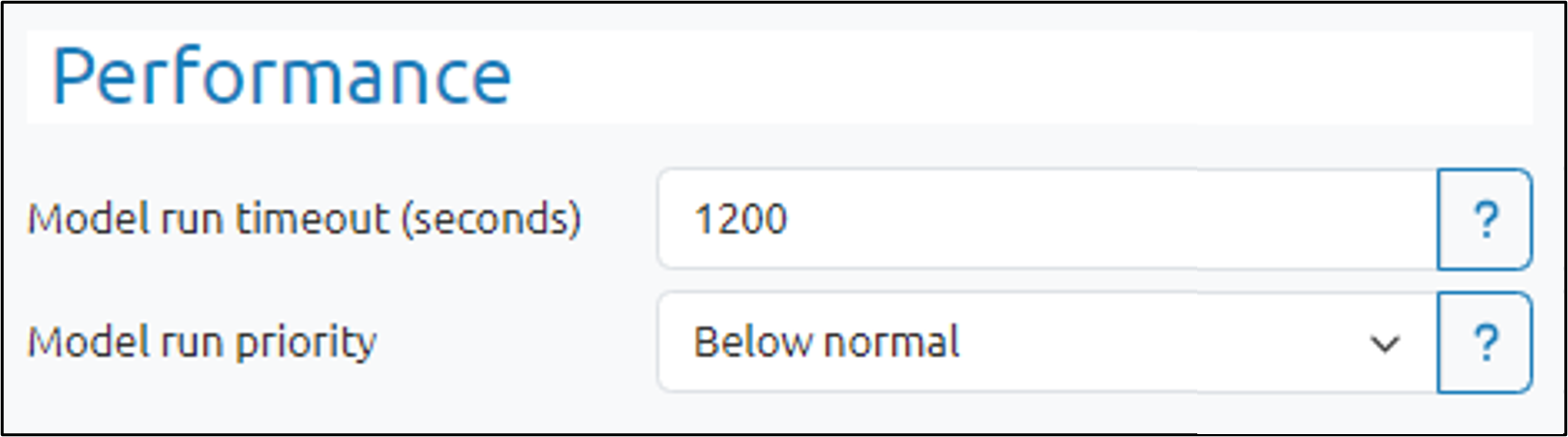
In the Model run timeout field, enter the number of seconds after which the execution is terminated, and the model is considered to have failed. The value must be a positive number.
Use the Model run priority pulldown to select the priority class for child processes that build and run models as well as run the R postprocess script. Choose from: Normal, Below normal, or Idle. (Note that Below normal is recommended to maintain user interface responsiveness.)
Directories options
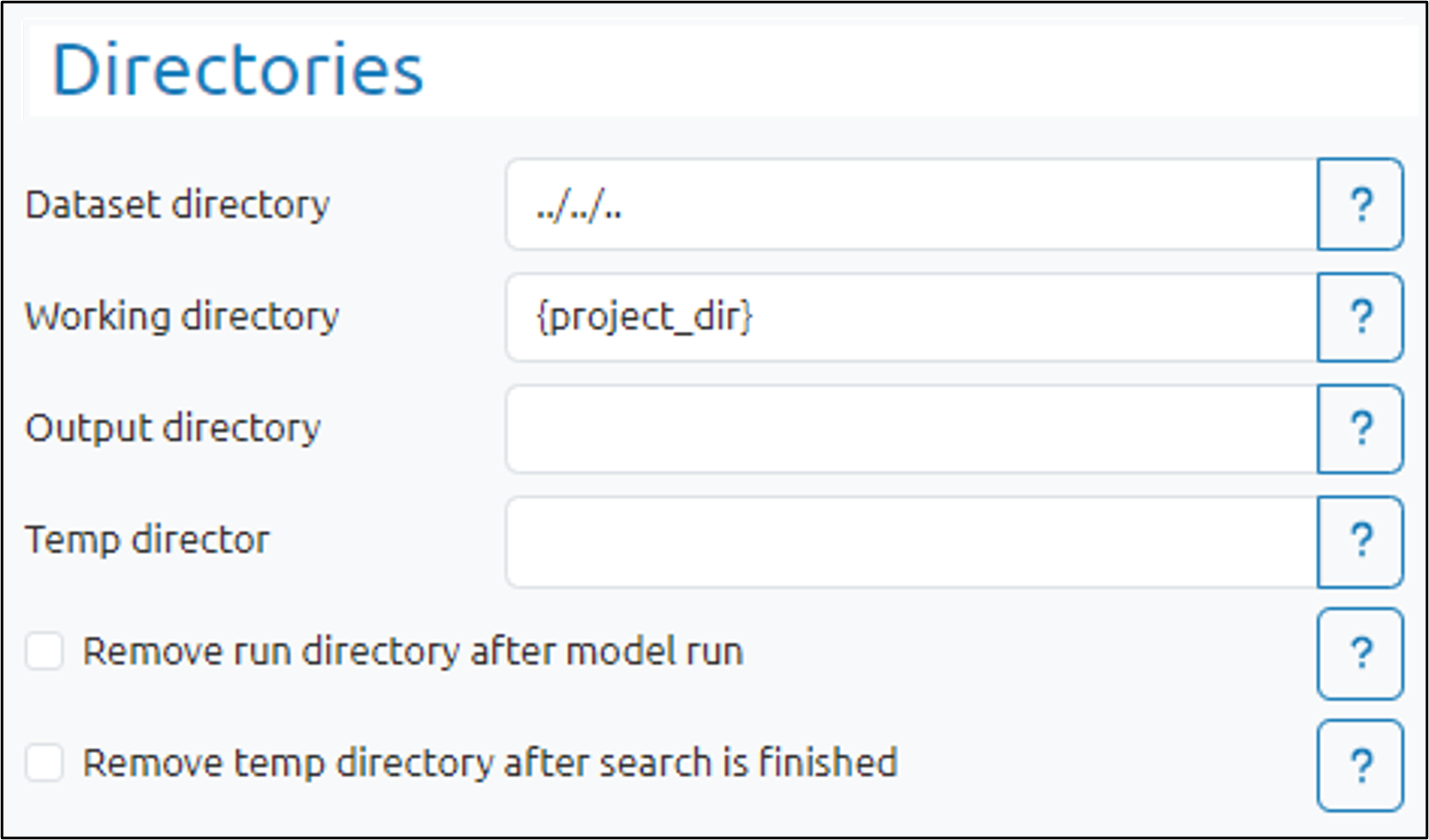
Enter the directory where datasets are located in the Dataset directory field.
Enter the project’s working directory in the Working directory field.
This is the default location of output and temp folders if none are specified below.
Enter the directory where pyDarwin output will be stored in the Output directory field.
Enter the parent directory for all model run directories in the Temp directory field.
This is where all folders for every iteration are located.
Check the Remove run directory after model run box to delete the run directory once the run completes.
If unchecked, model files are retained in the run directory, but all other files will be removed.
Check the Remove temp directory after search is finished box to delete the entire temp directory after the search is finished or stopped. (This option does not affect searches that are run on a grid.)
Model cache options
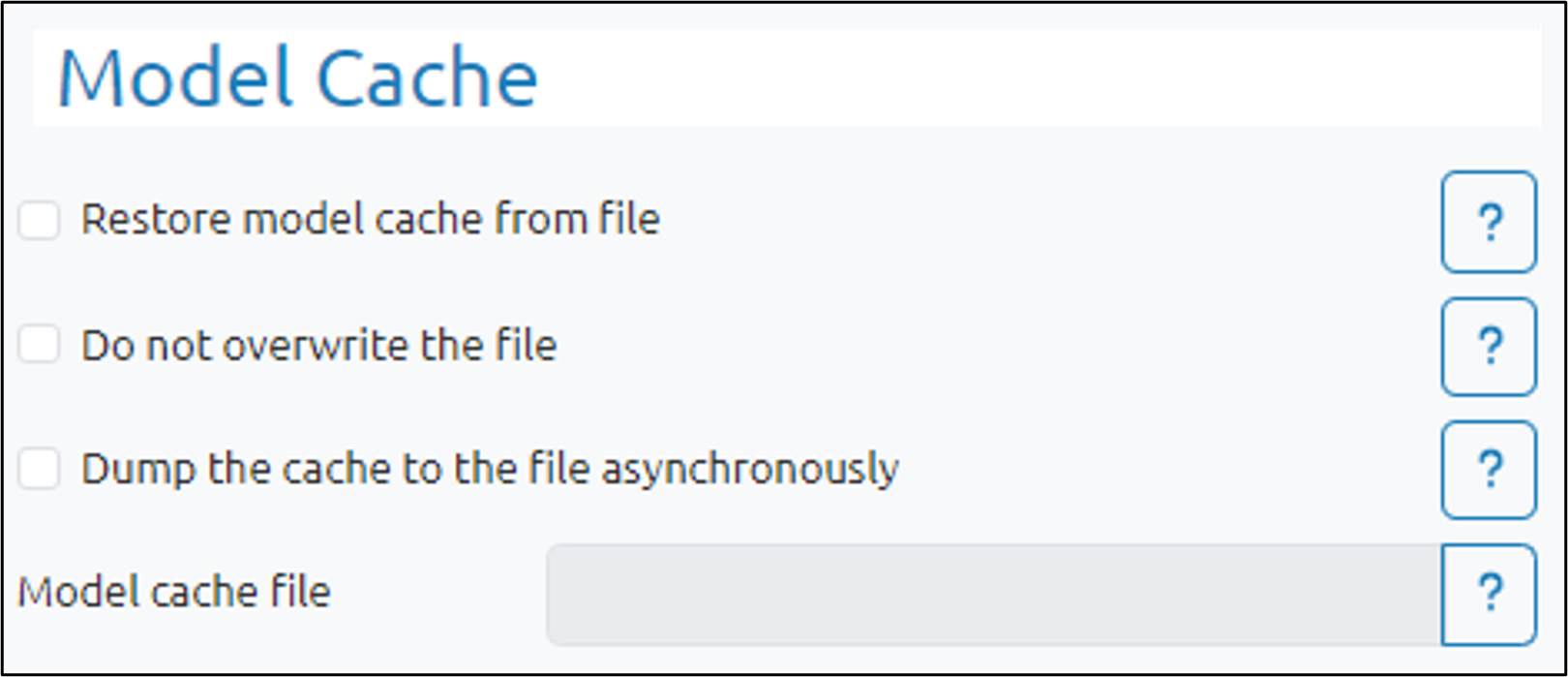
Check the Restore model cache from file box to load settings from a previously saved file, specified in the Model cache file field.
Check the Do not overwrite the file box to make the cache file readonly.
Check the Dump the cache to the file asynchronously box to have the model runs for the next iteration continue immediately after the dump is called.
For every iteration, all models are dumped into the cache file. By default, it is done synchronously, meaning no further computations are performed until the cache file is written. Checking this option tells pyDarwin to dump the file asynchronously and in a separate thread so the next iteration of the model runs can continue.
Custom options
Enter a list of JSON fields in the text field, each option on a separate line, using the format:
“option1”: 100,
“option2”: “yes”
These options will be concatenated to the options.json file.