The NONMEM object runs NONMEM models by using NONMEM control files and datasets. The results are returned to Phoenix.
Note:Phoenix program plugins, such as the NONMEM object, assume that the corresponding third party software is installed and running properly.
Use one of the following to add a NONMEM object to a Workflow:
Right-click menu for a Workflow object: New > NONMEM > NONMEM Shell.
Or Main menu: Insert > NONMEM > NONMEM Shell.
Or right-click menu for a worksheet: Send To > NONMEM > NONMEM Shell.
Note:To view the object in its own window, select it in the Object Browser and double-click it or press ENTER. All instructions for setting up and execution are the same whether the object is viewed in its own window or in Phoenix view.
This sections contains information on the following topics:
•Importing/Writing the code to access the external program
Global preferences are available to the user. Some third party tool objects require certain global settings to be specified prior to use. There are optional settings to enable editing of scripts in external programs from within Phoenix. Some optional preferences can streamline the workflow by automatically filling in or setting options in the object’s UI with information entered by the user in the Preferences dialog.
To set up access to the external program
Select Edit > Preferences.
In the Preferences dialog, select the NONMEM in the menu tree.
Enter the path to the batch file in the first field.
Or click Browse to locate and select the file/directory.
Click Test to make sure the correct file is selected.
To specify a development environment
There is a Development Environment section available on the preference pages. When the development environment is defined in this section, users can access that environment from the NONMEM object’s Options tab with the Start button. This allows users to edit scripts in other specified environments, and then pull the updated scripts back into Phoenix, at which time, the script can be executed from Phoenix and the output processed through the normal Phoenix workflow.
In the Command field, enter the directory path to the executable.
Or click Browse to locate and select the file.
In the Arguments field, enter any arguments/keywords to use when starting up the environment.
To define a default output location
Setting the output folder in the Preferences dialog eliminates the need to enter the information in the Options tab for each run. The fields will automatically be filled with the paths entered here.
Enter the directory path in the Default Output Folder field or use the Browse button.
Note:If the user specifies a default output location, the user must ensure that they have write access.
Turn on the Create a unique subfolder for each run checkbox to generate and then store the output from each run in a new subfolder of the output folder.
The Setup tab allows mapping of datasets and control files to the object. The Mappings panel(s) of the Setup tab displays the column headers specified in the control file. The Text panel allows users to map a control file to the object and view the contents.
Context associations for NONMEM objects change depending on the column headers, or input, defined in the control file. Some common mapping contexts associated with NONMEM are listed in “Common NONMEM context definitions”.
Common NONMEM context definitions
The following context definitions are common NONMEM variable names. They are not representative of all NONMEM variable names. Required context mappings are colored orange in the Mappings panel.
None: Exclude data type from analysis and output.
ID: Subject identification number.
AMT: Dose given at dosing time or time zero for observation records.
DOSE: Dose given to each subject.
TIME: Blood sampling times.
When using the Dose-Effect model, TIME is required as an input field in data, even though it is not used in analysis. You can create a dummy TIME column and map it work around this restriction.
CONC_DV: Typically drug concentration in plasma, but can be any dependent variable.
MDV: Missing dependent variable.
AGE: Age in years.
WT: Weight in kilograms.
ISM: Is male or is not male. In the column, 1=male, and 0=female.
CLCR: Creatinine clearance in mL per minute.
The Options tab is used to define a location for the output, access development environment, and start a remove execution.
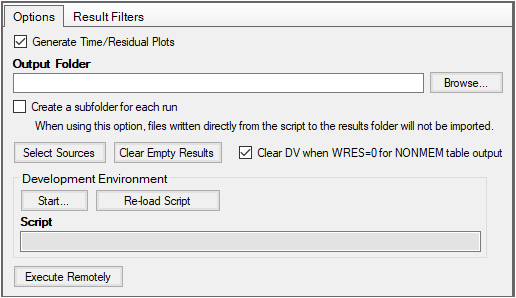
Entering an output location is optional. If a directory is not specified then Phoenix places output in a temporary folder that is deleted after Phoenix is closed. This may be preferred when sharing third party tool projects with other users, as the output folder is machine specific and may not exist on other machines. If users want to save the results from a third party tool object run to a disk, then they must either specify an output folder or manually export each result to disk.
Enter the output folder path in the field.
Or click Browse to specify the output folder location.
Turn on the Create a subfolder for each run checkbox to add a new results folder in the specified output location each time the object is executed.
This option prevents the output from being overwritten with each run, especially if the default output folder option, under Edit > Preferences, is being used.
Click Select Sources to include additional files along with the mapped input.
As an example, if a NONMEM object creates an MSF file that contains the estimates to full precision, then a second NONMEM object can use the MSF file as an Input File source.
Note:The Select Sources button in a NONMEM object’s Options tab can only access workflow objects. It cannot access items that are in the Data or Code folders. To access items in the Data or Code folders, use  in the toolbar for the Setup tab.
in the toolbar for the Setup tab.
Click the Clear Empty Results to remove any results published by the object that are empty.
Turn on the Clear DV when WRES=0 for NONMEM table output checkbox to clear the cell in the DV column for rows where the WRES column value equals 0.
To start the development environment, click Start in the Development Environment section of the Options tab.
The development environment as configured in the Preferences dialog is started. (See “To specify a development environment”.)
Note:NONMEM requires that a dataset be mapped to the object before the development environment will start.
When script work is completed, click Reload Script to bring the modified script into Phoenix for use in the next execution of the object.
The following are available only for a NONMEM object:
Select the version of NONMEM to use when the object is executed. The versions are defined in the Preferences dialog, see “To set up access to the external program”.
Use the Generate Time/Residual Plots checkbox to control which plots are generated. These plots are required for some types of comparisons. In other cases, the type of model and data are not appropriate for the automatically generated plots, and can cause errors during the execution, in which case the user can uncheck this option.
Allows specification of how different results files from the external program should be imported. Phoenix first looks for the first rule to match a file and uses that rule to import the object. The order of the rule matching is: Always Import (using normal import methods), Max File Size (will create a shortcut), Shortcut Files, Binary Files (using normal import methods). The user creates filter criteria based on filename patterns. If a maximum file size is specified, any file larger than the entered value will always be imported as a shortcut (unless the file matches filter criteria in the Always Import list).
Importing/Writing the code to access the external program
The NONMEM object must have code that will allow it to initiate the external program and submit jobs. The code can be stored as a control file, imported into the project, and mapped to the object, or the code can be directly entered into the object.
•Import and map file containing code
Import and map file containing code
Select a project or workflow in the Object Browser and then select a third party tool object from the Insert menu.
Select the File > Import menu option (or use one of the File > Custom Import options).
Navigate to and select the file(s) to import in the Import File(s) dialog.
Imported scripts or control/model files are added to the Code folder in the Object Browser.
Use the pointer to select and drag a dataset from the Data folder to the object’s data mappings panel.
The dataset is mapped to the object’s Mappings panel and the dataset name is displayed beside the primary data input in the Setup tab list.
Click the option buttons in the Mappings panel to map/unmap a data type in the dataset to the desired context. Contexts that must have data mapped to them so the object can perform its function are shaded orange.
Instead of importing and mapping a control file, users can write their own code or copy and paste code from another source. (For more information on the text editor, see http://www.syncfusion.com/products/user-interface-edition/windows-forms/edit/overview.
To enter the code manually, check the Use internal Text Object checkbox.
If a script/control file is already mapped, a message is displayed that asks if the mapped file should be copied to the internal text editor.
Click Yes to allow editing of the currently imported file.
Click No to remove the imported control file.
Type the code directly in the field.
When entry or modifications are complete, click Apply.
Some important things to consider when entering code in the Text panel versus importing and mapping a script/control file are:
Apply must be clicked for the code entered or modified to be accepted.
Changes made in the Text panel are not applied to the file on the disk.
The script can be modified either in the Code folder or in the object itself and these are kept in sync.
Once the user switches to Use Internal Text, any subsequent changes are not kept in sync with the script in the Code folder.
Below are additional notes.
-
Changes made to the $INPUT record are reflected in the Dataset Mappings panel. Changes made to a mapped control file do not change the control file in the Code folder.
-
Any blanks or tabs before statements should be removed prior to executing in Phoenix. Otherwise, the statement will be ignored.
-
Use only upper case when the specifying PHXTBL in the control file. Otherwise, duplicate NONMEM output files will result since Phoenix generates a file named “PHXTBL” by default for use with the NONMEM Comparer object.
-
Input statements should not contain equal strings. For example, $INPUT ID TIME DV=DROP LNDV=DV MDV AMT RATE EVID DOSE should be changed to $INPUT ID TIME DV MDV AMT RATE EVID DOSE and the column LNDV mapped to DV.
-
If a NONMEM control statement calls to perform more than one fit, the control statement should be split and the models run in sequence. For example, it should not be used with multiple $PROB input files, superproblems, or $PRIOR routines.
In order for NONMEM to call Ifort variables within Phoenix the setup of nmfe7.bat needs to be modified to support specific compilers. The modifications needed are:
set F77HOME=C:\Program Files\Intel\Compiler\Fortran\10.1.011
if '%F77VERHOME%==' set F77VERHOME=%F77HOME%
call “%F77VERHOME%\Ia32\bin\ifortvars.bat”
-
If NONMEM is installed on the same server as Phoenix, edit the path in the system environment so that gfortran comes ahead of the Certara software (i.e., edit the path so that C:\Program Files\gfortran\libexec\… comes first in the path, before C:\Program File s(X86)\Certara\Phoenix\MinGW…) to avoid issues where NONMEM errors out.
The input can be defined within the script as a shortcut by adding ;PHX_SHORTCUT to the end of the $DATA statement.
$DATA FILE [OPTIONS];PHX_SHORTCUT
FILE will be replaced with the path to the file.
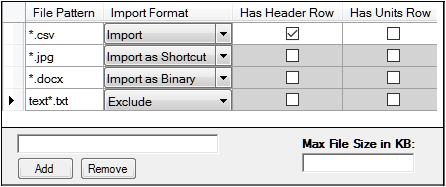
The Result Filters tab allows users to define filters that determine whether files of a certain name or size are returned to Phoenix as a shortcut, a binary file, a complete copy, or returned at all.
Type the file pattern to serve as a filter into the field near the bottom of the tab and click Add. (Enter full file names or use the wildcard “*”, e.g., *.txt.)
To remove a pattern from the list, select it and click Remove.
For each pattern, select how files matching the pattern are to be handled:
Import: Default file handling for imported data of that file type is used to import the file
Import as Shortcut: The file itself is not imported, however, a shortcut is created that points to the complete file
Import as Binary: The file is imported as a binary object, with no conversion to any specific Phoenix type
Exclude: The file is not imported
Should a file match several specified patterns, the precedence of processing is: Exclude, Import, Shortcuts, Binary.
For .csv and .dat output files, check the Has Header Row box to indicate that files matching the file pattern have a header row.
For .csv and .dat output files, select the Has Units Row option to indicate that files matching the file pattern have a units row.
Enter maximum size that an imported complete file can be in the Max File Size in KB field.
Any file that exceeds this size is imported as a shortcut (unless the file matches a File Pattern whose Import Format is set to Import).
Click  .
.
Or to run the job remotely, click Execute Remotely in the Options tab.
Executing a third party tool object remotely sends the job to the server that is defined in the Preferences dialog (Edit > Preferences > Remote Execution). See “Phoenix Configuration” for instructions. The project is saved automatically.
The project must have been saved at least once prior to executing on RPS, otherwise execution will not pass validation and a validation message will be generated.
At this point, the step being executed on RPS, along with any dependent objects, has been locked. It is now safe to close the project or to continue working in Phoenix.
In Phoenix, some objects in a workflow allow the user to click and execute the last object in a chain and it will re-run any necessary objects earlier in the workflow. This is true for a NONMEM object.
The results are displayed on the Results tab. The output falls into the following categories:
Output Data: Datasets in tabular form
Text Output: Settings files, log files, and other text output
Other: Other kinds of files, for example: documents, export files, binary files, etc.
Images: Graphs or other images in recognized image formats (jpg, tiff, emf, etc.)
The NONMEM object generates the following output:
|
Output Data |
Content |
|
PHXTBL |
Table that summarizes ID, TIME, CWRES, DV, PRED, RES, and WRES. |
|
Summary |
The Summary table contains the following: total number of observations, total number of subjects, lengths of theta, minimum objective function value, total number of parameters, AIC, BIC, and the conditions for estimation. |
|
Additional Output |
Content |
|
GFCOMPILE |
Lists the Digital FORTRAN compiler messages created during NONMEM execution. |
|
FCON |
NONMEM control stream file. |
|
FDATA |
Dataset used with NONMEM. |
|
FREPORT |
Lists the subroutines used to generate the commands used to create the NONMEM model. |
|
FSTREAM |
NONMEM file control stream. |
|
FSUBS |
Lists the generated FORTRAN subroutines. |
|
PRDERR |
Lists errors encountered during execution of the PRED subroutine. |
|
Raw_Output |
The unparsed output directly from NONMEM. |
|
Settings |
The input worksheet used and the options selected. |
|
stdout |
Warnings and errors (if any) for problems. |
If a NONMEM control file has a $COV statement then the total number of parameters in the model are calculated in the Summary table. If there is no $COV statement, then users can specify the number of parameters in the control file by adding this comment prior to the $EST statement:
; #parameters= X
where X is an integer.
If the control file contains several $EST statements the number of parameters comment preceding the estimate statement(s) would be used.
If the number of parameters is available then AIC and BIC are calculated:
AIC=Min. Val. Of Obj. Func+2*(Tot. #Params)
BIC=Min. Val. Of Obj. Func+(Tot. #Params*Loge(Tot.#obs))
Note:To correctly read in TABLE files generated by NONMEM, the ONEHEADER command must be present in the control file as part of the TABLE statements.
|
Output Data |
Content |
|
Sigma SE |
Standard error(s) of the observation error variance estimates if the $COV statement is in the control file. |
|
Theta |
Fixed effect estimates. |
|
Omega |
Estimates of the elements of the random effect(s) covariance matrix. |
|
Sigma |
Estimates of the observation error variance(s). |
|
Table 1 |
NONMEM generated table files. |
|
COVARIANCE MATRIX OF ESTIMATE |
Covariance matrix for the model parameter estimates if the $COV statement is in the control file. |
|
CORRELATION MATRIX OF ESTIMATE |
Correlation matrix for the model parameter estimates if the $COV statement is in the control file. |
|
Theta SE |
Standard errors of the fixed effect estimates (thetas) if the $COV statement is in the control file. |
|
Omega SE |
Standard errors of the random effect covariance matrix element estimates (omegas), if the $COV statement is in the control file. |
|
(Optional) File name of the TABLE statement |
NONMEM generated table files. |
Users can double-click any plot in the Results tab to edit it. (See the “Options tab” description for plots for more details.) Plot edits are maintained during consecutive NONMEM modeling runs.
|
Plot |
Content |
|
DV VS PRED |
Plot of dependent variable in the X-axis and predicted variable in the Y-axis. |
|
PRED VS CWRES |
Plot of predicted variable in the X-axis and conditional weighted residuals in the Y-axis. |
|
PRED VS RES |
Plot of predicted variable in the X-axis and residual variable in the Y-axis. |
|
PRED VS WRES |
Plot of predicted variable in the X-axis and weighted residuals in the Y-axis. |
|
TIME VS DV |
Plot of time in the X-axis and dependent variable in the Y-axis. |
|
TIME VS CWRES |
Plot of time in the X-axis and conditional weighted residuals in the Y-axis. |
|
TIME VS PRED |
Plot of time in the X-axis and predicted variable in the Y-axis. |
|
TIME VS RES |
Plot of time in the X-axis and residual variable in the Y-axis. |
|
TIME VS WRES |
Plot of time in the X-axis and weighted residuals in the Y-axis. |
|
(Optional) Plot names in the $SCAT statement |
NONMEM generated plots. SCAT statements in NONMEM code will only automatically generate a plot in Phoenix if there is a TABLE statement in NONMEM that contains the variable being plotted. |
|
Text Output |
Content |
|
Settings |
The worksheet with the updated concentration column. |
