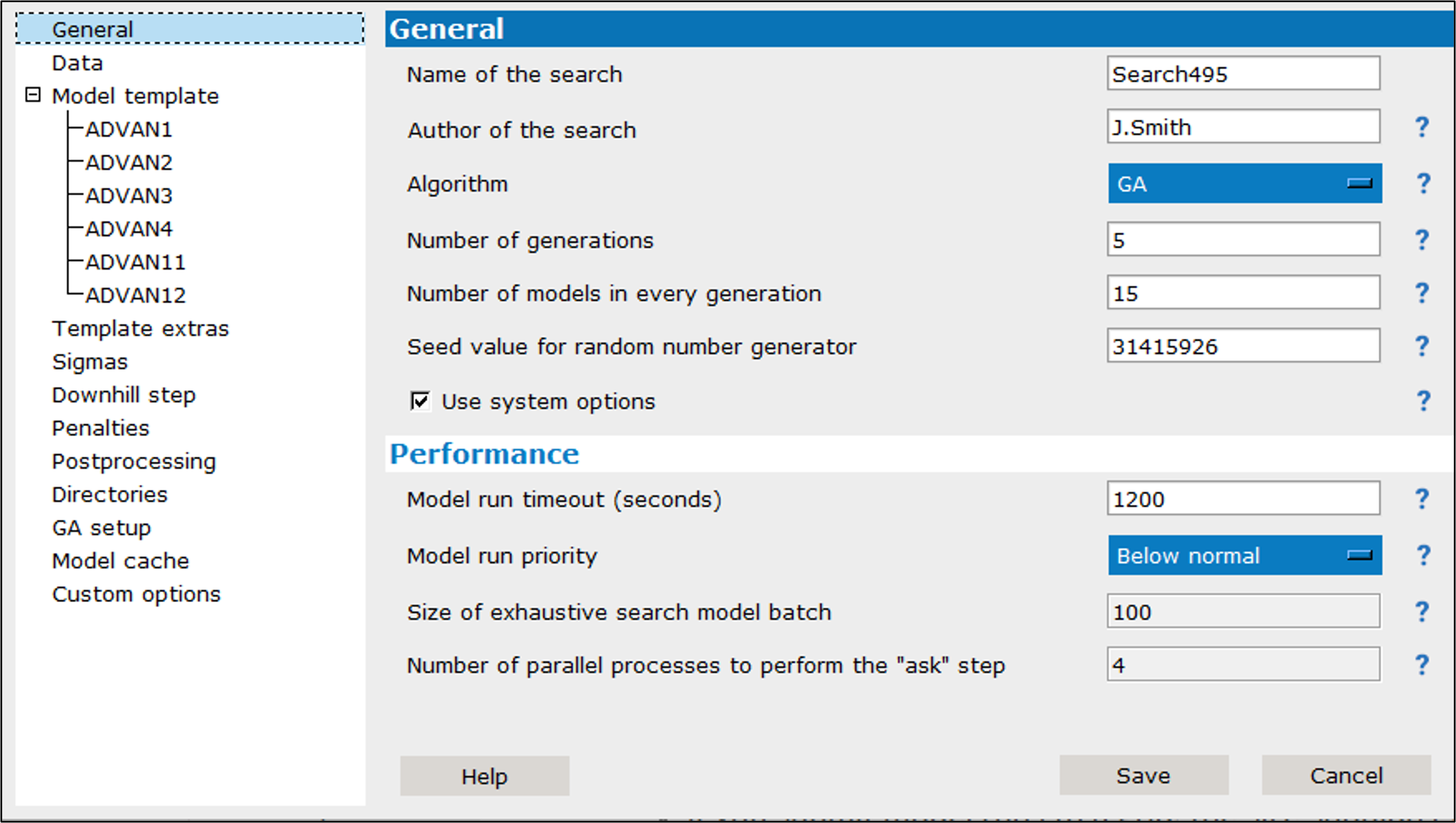
In the Name of the search field, enter a title with which to refer to this search.
In Author of the search field, enter the name of the person creating this search.
Select the search Algorithm from the pulldown.
Options:
EX: Exhaustive search, in which the search space is initially represented as a string of integers - one for each dimension.
GA: Genetic Algorithm that reproduces the mathematics of evolution/survival of the fittest.
GP: Gaussian Process that involves specifying the form of the prior and posterior distribution.
RF: Random Forest consists of splitting the search space into “good” and “bad” regions.
GBRT: Gradient Boosted Random Tree is similar to RF, but progressively builds the tree, calculating a gradient of reward/fitness with each decision.
In the Number of generations field, set the number of iterations of the search algorithm to run (not used by GBRT or EX algorithms).
In the Number of models in every generation field, set the number of models to create in each generation. This is the population of each generation (not used by EX algorithm).
In the Seed value for random number generator field, enter a positive integer to serve as the seed for the random number generator (not used by EX algorithm).
Check the Use system options box to override corresponding settings with those defined in a separate .json file that is specified on the “Darwin settings” preference page. This option removes the need to edit certain settings (e.g., the nmfe path or Rscript path) each time you change environments. (GA GP RF GBRT EX).
In the Model run timeout field, enter the number of seconds after which the execution is terminated and the model is considered to have failed.
From the Model run priority pulldown, select the priority class for child processes that build and run models as well as run R postprocess script. Choose Normal or Below normal. (Note that Below normal is recommended to maintain user interface responsiveness.)
In the Size of exhaustive search model batch field, enter the number of models to run as a batch. (Only applies to the EX algorithm.)
In the Number of parallel processes to perform the “ask” step field, enter the number of processes to run in parallel when generating samples for the next generation (not used by GA or EX algorithms).