Applicable to Gaussian and user-defined log likelihood data. The Naive pooled engine, when applied to population data, treats all observations as if they came from a single individual in that it ignores inter-individual variations in 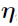 values. All s are forced to zero, and no
values. All s are forced to zero, and no 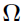 parameters are computed, only
parameters are computed, only 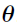 and
and 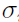 . The engine can also be applied to a single individual, to individuals separately as a series of individual fits in a multiple individual dataset, or to all individuals collectively in a population model. When applied to all individuals in population mode, the engine pools the data for evaluation into a single individual log likelihood function that contains no random effect parameters, but respects inter-individual differences in dosing and covariate values.
. The engine can also be applied to a single individual, to individuals separately as a series of individual fits in a multiple individual dataset, or to all individuals collectively in a population model. When applied to all individuals in population mode, the engine pools the data for evaluation into a single individual log likelihood function that contains no random effect parameters, but respects inter-individual differences in dosing and covariate values.
The engine minimizes the exact negative log-likelihood, either as a Gaussian or user-specified function. No approximations are necessary since there is no population distribution and hence no joint likelihood to integrate.
The goal of the Naive pooled engine is just to find the optimal parameters 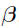 and the support point
and the support point 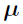 . The same quasi-Newton algorithm as used in the other engines performs the search for and . As with FO, FOCE ELS, and Laplacian, iterations simply correspond to iterations of the quasi-Newton optimization algorithm. As with FO, in principle only a single pass through the quasi-Newton method is required, but in the Phoenix NLME implementation the optimization is repeated from the final value of the previous run until successive runs yield the same log likelihood to within a tolerance of 0.001.
. The same quasi-Newton algorithm as used in the other engines performs the search for and . As with FO, FOCE ELS, and Laplacian, iterations simply correspond to iterations of the quasi-Newton optimization algorithm. As with FO, in principle only a single pass through the quasi-Newton method is required, but in the Phoenix NLME implementation the optimization is repeated from the final value of the previous run until successive runs yield the same log likelihood to within a tolerance of 0.001.
Naive pooled engine is applicable to Gaussian and user-defined log likelihood data. However, it is not really for population analysis.