Consider a trial testing the effects of two treatments, Test (T) and Reference (R). Suppose that n subjects are randomly assigned to the first sequence, TR, in which subjects are given treatment T first and then treatment R following an adequate washout period. Similarly, m subjects are assigned to the RT sequence. Y represents the outcome of the trial (for example Cmax or Tmax) and yijk is the value observed on sequence i (i=1,2), subject j (j = 1,2,…,n, n+1,…n+m) and period k (k=1,2). Treatment is implied by sequence i and period k, for example i=1 and k=1 is treatment T; i=1 and k=2 is treatment R. The data are listed in columns 1 through 4 of the following table, and column 5 gives the within-subject difference in Y between the two periods, where:
dij = yij1 – yij2
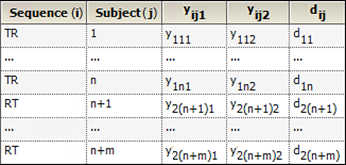
Then the n*m crossover differences (d1i – d2j)/2 are computed, along with the median of these n*m points. This median is the Hodges-Lehmann estimate of the difference between the median for T and the median for R.
Crossover Design supports two data layouts: stacked in same column or separate columns. For “stacked” data, all measurements appear in a single column, with one or more additional columns flagging which data belong to which treatment. The data for one treatment must be listed first, then all the data for the other. The alternative is to place data for each treatment in a separate column.