Testing the Phoenix installation
The following instructions test the installation of Getting Started by using a number of the sample files provided with the software. This chapter is not intended as a full validation of the product. It is intended to test for proper installation of major components of the application.
A set of Validation Suite Products is available from Certara. Contact the Certara sales department for more information.
Start Phoenix and create a new project
Double-click the Phoenix icon (![]() ) on your desktop to start Phoenix.
) on your desktop to start Phoenix.
Note: AutoPilot users running on 64-bit operating systems should run the 32-bit version of Phoenix (Phoenix32) as opposed to the 64-bit version. The Phoenix desktop icon should be updated to reference the Phoenix32 executable as well.
Select File > New Project to create a new project.
A new project is created in the Object Browser.
Name the new project Install Test.
The left panel’s default view is the Object Browser, which contains the project, and the other folders and objects that are contained in the project. The right viewing panel’s default view is blank, unless one of the project folders or the workflow is selected.
Creation of Install Test project denotes a successful installation test.
Confirm license installation
The ability to execute different Phoenix plug-ins depends on the license type installed. Use the Preferences dialog to check the installed Phoenix license(s).
1. Select Edit > Preferences to access the Preferences dialog.
2. Select Licensing > License Management to access the list of available licenses.
3. Confirm that the purchased license or licenses are listed in the Licenses panel.
Confirm plug-in startup
The Phoenix architecture is based on a series of plug-ins that allow different features to be enabled or disabled. Phoenix initializes these plug-ins when the application starts. The default setting is for all plug-ins to initialize when Phoenix starts. The plug-in initialization is independent of the installed license(s).
1. In the Preferences dialog, click Plugins to view the list of available plug-ins.
The Plugins panel on the right contains three tabs: General, System, and Non-loaded. Each plug-in has two possible states, Started and Stopped. All plug-ins are started the first time Phoenix is started.
2. Select the General, System and Non-loaded tabs to view the state of each plug-in type and confirm they are started.
3. Press OK to exit the Preferences dialog.
Import a dataset
The dataset Bguide1.dat is used to test key Phoenix functions.
1. Select File > Import, click ![]() (Import File icon), or select Import from the Data Folder right-click menu in the Object Browser.
(Import File icon), or select Import from the Data Folder right-click menu in the Object Browser.
The Import File(s) dialog is displayed.
2. Navigate to <Phoenix_install_dir>\application\Examples\WinNonlin\Supporting files).
3 Select the file Bguide1.dat and press Open.
The File Import Wizard dialog is displayed. The dialog is used to assign options for how the data are imported and presented.
4. Press Finish.
The dataset is added to the project Data folder and the worksheet is displayed in the right viewing panel.
Create a plot
1. Right the Workflow object and select New > Plotting > XY Plot.
The XY Plot object is added to the workflow in the Object Browser and is automatically opened in the right viewing panel. The default view of an object is the Setup tab, which contains all the steps necessary to set up an object.
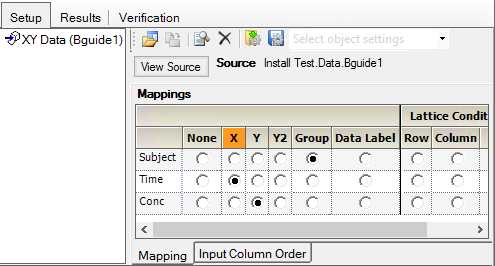
2. Drag the Bguide1 worksheet from the Data folder to the XY Data Mappings panel.
3. Use the option buttons in the XY Data Mappings panel to map the columns to the contexts as follows:
Subject to Group.
Time to X.
Conc to Y.
4. Click ![]() (Execute icon) to execute the workflow.
(Execute icon) to execute the workflow.
XY Plot results:
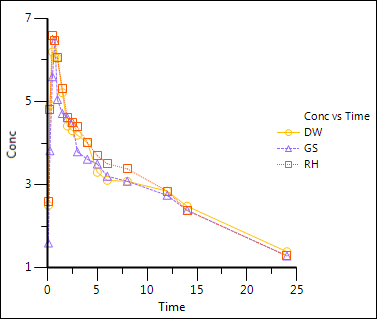
Create a table
Now use the Bguide1 dataset to test the Table object and its summary statistics function.
1. Add the Table object to the workflow by right-clicking the Workflow object and selecting New > Reporting > Table.
2. Drag Bguide1 from the Data folder to the Table object’s Main Mappings panel.
The dataset Bguide1 is mapped as the input source for the Table object.
3. Use the option buttons in the Main Mappings panel to map the columns to the contexts as follows:
Subject to Stratification Row.
Conc to Data.
Leave Time mapped to None.
4. In the Options tab below the Setup tab, specify the table type by selecting Table 1 - Column Summary by Row Stratification from the Table Type menu.
5. Check the Page Break on Row Stratification box.
6. Select the Statistics tab, located below the Setup tab.
7. Press Select All to select all output statistics.
8. Execute the object.
The results are presented as three HTML tables in the Results tab. Compare the tables in the Results tab to the tables pictured below.
Resulting HTML table for subject DW:
Resulting HTML table for subject GS:
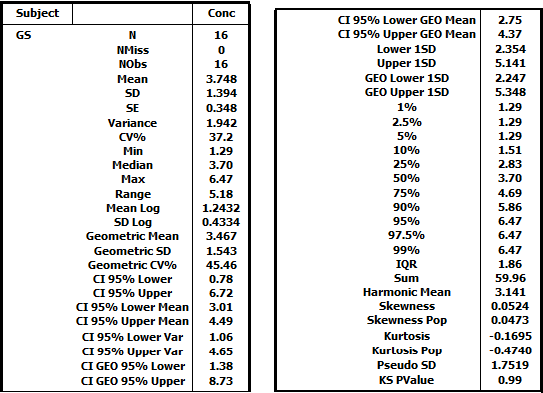
Resulting HTML table for subject RH:
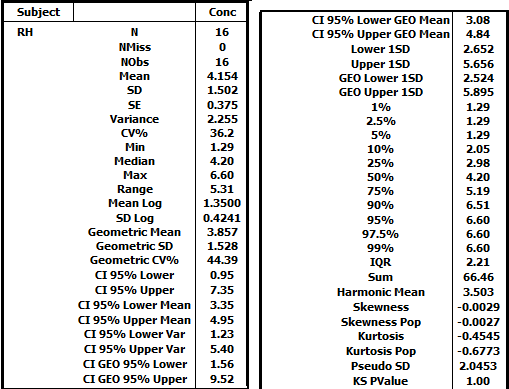
Confirm noncompartmental analysis functions
1. Select File > Load Project. The Load Project dialog is displayed.
2. Navigate to <Phoenix_install_dir>\application\Examples\WinNonlin.
3. Select Multiple_Profiles.phxproj and press Open.
This project contains:
A dataset worksheet (profiles)
A worksheet of dosing information (Dosing published from NCA)
An XY Plot object
An NCA model object
A Descriptive Statistics object
A Data Wizard object
An X-Categorical XY Plot object
4. Expand the Workflow node in the Object Browser.
5. Select the NCA model object.
6. Select items in the Setup tab list to explore the data mappings and option settings.
7. Execute the object.
Text output
The Core output contains the model settings and the same data as the worksheets but presented in plain ASCII text. If there were errors in the model they would be listed here. Part of this file is shown below:
…
Model: Plasma Data, Extravascular Administration
Number of nonmissing observations: 12
Dose time: 0.00
Dose amount: 100.00
Calculation method: Linear Trapezoidal with Linear Interpolation
Weighting for lambda_z calculations: Uniform weighting
Lambda_z method: Find best fit for lambda_z, Log regression
Compute Concentrations at: 75
Summary Table
-------------
Time Conc. Pred. Residual AUC AUMC Weight
min ng/ml ng/ml ng/ml min*ng/ml min*min*ng/ml
------------------------------------------------------------
0.0000 0.0000 0.0000 0.0000
5.000 340.3 850.8 4254.
10.00 1914. 6487. 5.636e+04
15.00 2069. 1.644e+04 1.818e+05
20.00 1417. 2.529e+04 3.329e+05
30.00 788.8 3.659e+04 5.983e+05
45.00* 496.4 460.9 35.54 4.623e+04 9.434e+05 1.000
60.00* 372.8 357.2 15.63 5.275e+04 1.279e+06 1.000
90.00* 204.3 214.6 -10.33 6.141e+04 1.890e+06 1.000
120.0* 124.1 128.9 -4.852 6.633e+04 2.389e+06 1.000
180.0* 39.25 46.52 -7.266 7.123e+04 3.048e+06 1.000
240.0* 19.32 16.79 2.531 7.299e+04 3.399e+06 1.000
The Settings file lists all the settings used to specify the noncompartmental analysis.
…
Sort: Subject, Form
Time: Time [min]
Concentration: Conc [ng/mL]
Carry:
Dosing: (Internal)
Slopes: (Internal)
Partial Areas: (Internal)
Therapeutic Response: <None>
Units: (Internal)
Parameter Names: <None>
…
Plasma Model
Title=Processing Multiple Profiles with Model 200
Linear Trapezoidal Linear Interpolation
Sparse=False
Weighting=Uniform Weighting; 0
Dose Type=Extravascular
Dose Unit=ng
Dose Normalization=None
Compute Concentrations at: 75
…
Output data
The NCA object creates seven results worksheets: Dosing Used, Exclusions, Final Parameters, Final Parameters Pivoted, Partial Areas, Plot Titles, Slopes Settings, and Summary Table. Selections from the Final Parameters and Summary Table worksheets are shown below.
Final Parameters worksheet:
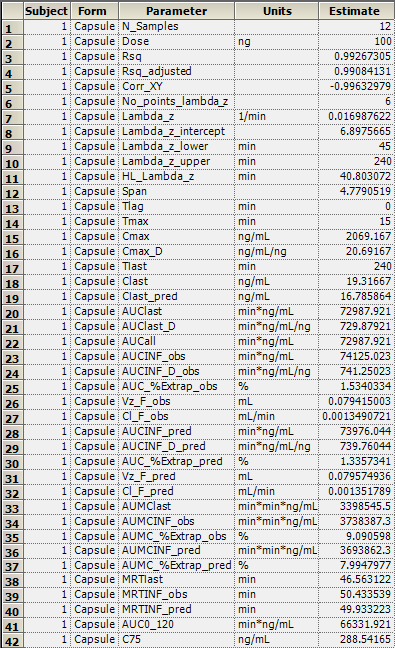
Summary Table worksheet:
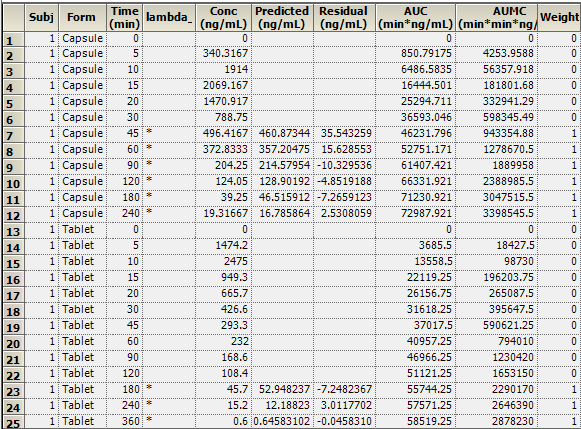
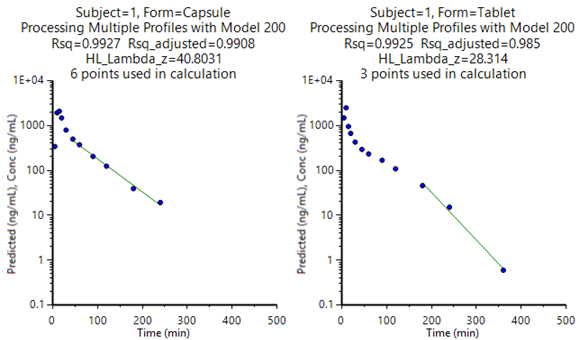
Plots
A total of 12 plots are generated; one for each of two formulations, for each of the six subjects. The first two charts for subject one are shown below.
Confirm pharmacokinetic modeling functions
1. Select File > Load Project.
The Load Project dialog is displayed.
2. Navigate to <Phoenix_install_dir>\application\Examples\WinNonlin.
3. Select PK_Model.phxproj and press Open.
This project contains:
A dataset worksheet (study1).
An XY Plot object.
A PK model object.
4. Expand the Workflow node in the Object Browser.
5. Select the PK Model object.
6. Select items in the Setup tab list to explore the model’s data mappings and option settings.
The imported PK Model object uses PK Model 3, which is a one-compartment model with 1st order absorption.
7. Execute the object.
Worksheet results
The PK Model object’s output worksheets partially include Condition Numbers, Diagnostics, Dosing Used, Final Parameters, Initial Estimates, Secondary Parameters, and Summary Table. The Final Parameters, Secondary Parameters, and Summary Table worksheets are shown below.
Final Parameters worksheet:

Secondary Parameters worksheet:
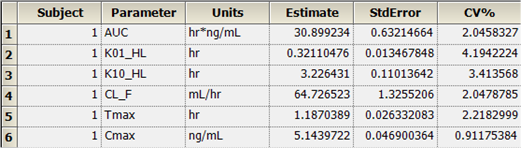
Summary Table worksheet:
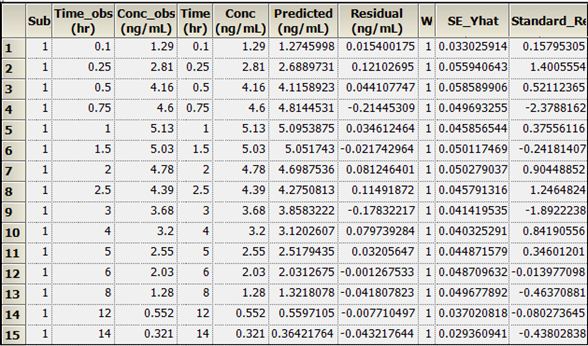
Text output
The Core output text results include all model settings and iterations, including the output from the worksheets. Any model errors would be listed here. Part of this file is shown below.
…
Listing of input commands
MODEL 3
NVAR 3
NPOI 1000
XNUM 2
YNUM 3
NCON 3
CONS 1,2,0
METH 2‘Gauss-Newton (Levenberg and Hartley)
ITER 50
INIT 0.25,1.81,0.23
MISS ‘.’
DATA ‘WINNLIN.DAT’
BEGIN
The Settings file lists all the settings used to specify the noncompartmental analysis. Part of this file is shown below.
…
Main: PK Model.Data.study1
Sort: Subject
Time: Time [hr]
Concentration: Conc [ng/mL]
Carry:
Dosing: (Internal)
Initial Estimates: (Internal)
Units: (Internal)
***** Other Parameters *****
…
PK 3-[PK]
Gauss-Newton (Levenberg and Hartley)
Convergence criteria of 0.0001 used during minimization process
50 maximum iterations allowed during minimization process
Plots
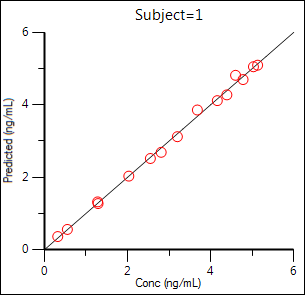
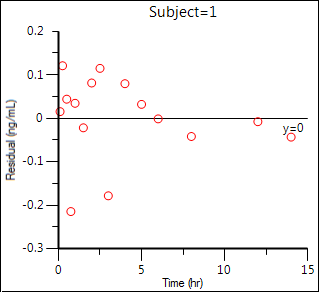
The plot results include Observed Y and Predicted Y vs X, Partial Derivatives Plot, Predicted Y vs Observed Y, Predicted Y vs X, Residual Y vs Predicted Y, and Residual Y vs X. Some plot results are shown below.
Observed Y and Predicted Y vs X:
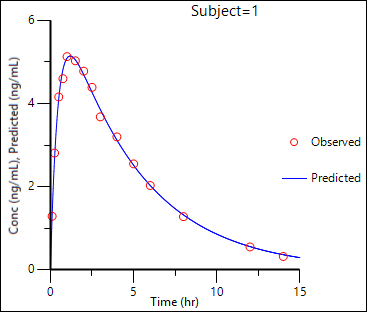
Predicted Y vs Observed Y:
Residual Y vs X:
Confirm bioequivalence functions
1. Select the Install Test project in the Object Browser.
2. Select File > Import.
3. In the Import File(s) dialog, navigate to <Phoenix_install_dir>\application\Examples\WinNonlin\Supporting files.
4. Select the file Seq2Per4.csv and press Open.
5. In the File Import Wizard dialog, press Finish.
The dataset is added to the project Data folder.
6. Right-click Workflow in the Object Browser and select New > Computation Tools > Bioequivalence.
The Bioequivalence object is added to the workflow in the Object Browser.
Note: The default settings for a new Bioequivalence model are Crossover as the type of study and Average as the type of bioequivalence.
7. Drag the Seq2Per4 worksheet from the Data folder to the Main Mappings panel.
The Seq2Per4 dataset is mapped to the Bioequivalence object.
8. Use the option button in the Main Mappings panel to map AUC to the Dependent context.
The following data types are automatically mapped to contexts when the dataset is mapped to the Bioequivalence model.
Sequence to Sequence.
Subject to Subject.
Period to Period.
Formulation to Formulation.
AUC to Dependent.
9. In the Model tab (located below the Setup tab), ensure that:
a. Crossover is selected as the Type of study.
b. Average is selected as the Type of Bioequivalence.
c. R is selected as the Reference Formulation.
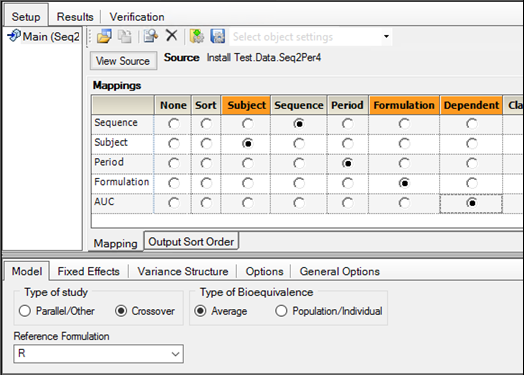
10. Select the Fixed Effects tab, located below the Setup tab.
Ln(x) is automatically selected in the Dependent Variables Transformation menu. Do not change this setting.
11. Execute the object.
Output data
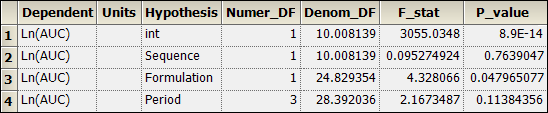
The bioequivalence model worksheet output partially includes Average Bioequivalence, Diagnostics, Final Fixed Parameters, Final and Initial Variance Parameters, Least Squares Means, and Sequential Tests. The Diagnostics, Final Variance Parameters, and Sequential Tests worksheets are shown below.
Average Bioequivalence worksheet:
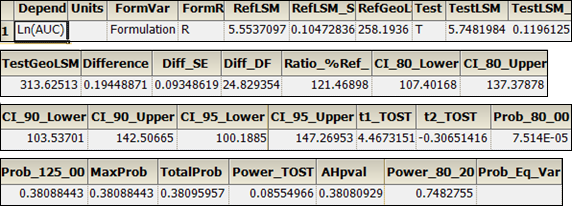
Diagnostics worksheet:
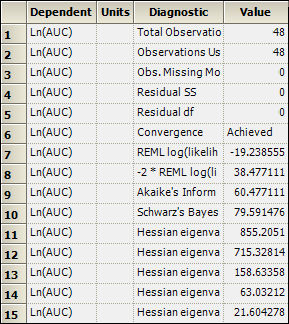
Final Variance Parameters worksheet:

Sequential Tests worksheet:
This concludes the Phoenix installation tests.
Test installation of Phoenix NLME
Users who have purchased a license for Phoenix NLME can use the Maximum Likelihood Models object to create and test population models. After Phoenix is installed, follow the steps below to confirm that population modeling is working correctly.
This example verifies that the Phoenix NLME license and the Minimal GNU C++ compiler are correctly installed and configured. It is not intended as a full validation of population modeling. If Phoenix is being used without population modeling functionality, then skip this installation test.
Note: For this installation test to work, users must have an active license for Phoenix NLME 8.4.
If any problems are encountered during this installation test, report the issue to Customer Support.
Start Phoenix and create a project
1. Double-click the Phoenix icon (![]() ) on your desktop to start Phoenix.
) on your desktop to start Phoenix.
2. Select File > New Project to create a new project.
A new project is created in the Object Browser.
3. Name the new project Installation Project.
Confirm population modeling functionality
1. Select File > Import.
2. In the Import File(s) dialog, navigate to <Phoenix_install_dir>\application\Examples\NLME\Supporting files.
3. Select theopp.csv and press Open.
4. In the File Import Wizard dialog, press Finish.
The dataset is added to the project Data folder and the worksheet is opened.
5. Select the Workflow object in the Object Browser.
6. Select File > Load Workflow Template.
7. In the dialog, navigate to <Phoenix_install_dir>\application\Examples\NLME\Supporting files.
8. Select Diagonal Model.phxtmplt and press Open.
Phoenix template files store information about settings and internal worksheets but do not store external data sources.
The template file adds a one-compartment, 1st order absorption model that uses weight as a covariate. The model uses the FOCE L-B (First Order Conditional Estimation with the Lindstrom-Bates iterative algorithm) run method.
9. Select the Structural, Parameters, and Run Options tabs to examine the model configuration.
The Parameters tab contains several sub-tabs that list fixed effects, random effects, and covariates.
10. Drag the theopp worksheet from the Data folder to the Main Mappings panel.
The theopp dataset is mapped to the Diagonal model and the study variables xid, dose, time, yobs, and wt are automatically mapped to the contexts ID, Aa, Time, CObs, and wt, respectively.
11. Execute the object.
12. Close the NLME Job Status dialog by clicking the X in the upper right corner.
Verify the results
1. Select the Verification tab.
The Verification Results state that the model successfully executed, and that no errors occurred.
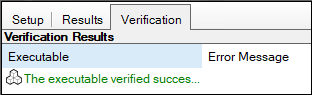
2. Select the Results tab.
The model object produces text files, plots, and worksheets. The output types are listed below.
Output data
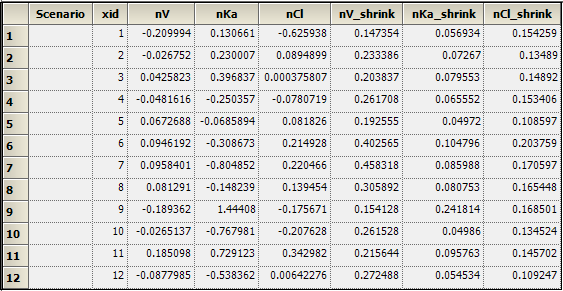
The model creates 23 worksheet results. Some of the output worksheets are Eta, EtaCovariate, Omega, and Theta. Not all worksheets listed under Output Data contain results.
Confirm the accuracy of some of the output to complete the installation test.
1. In the Output Data, select the Theta worksheet and confirm that the following estimates are the same (after rounding):
tvKa 1.556
tvV 0.455
tvCl 0.0403
stdev0 0.692
Theta worksheet:

Eta worksheet:
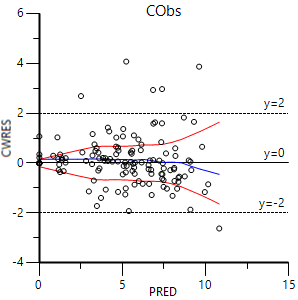
Plots
Thirty-nine plots are listed in the Plots section. Not all listed plots have results.
1. In the Plot output, select Pop CWRES vs PRED and compare it to the screen shot below:
Text output
The Maximum Likelihood Models object creates six text files. The Settings text file lists model settings, part of which is shown below.
…
Sort:
ID: xid
Aa: dose
Time: time
CObs: yobs
wt: wt
…
test(){
deriv(Aa = -Ka * Aa)
deriv(A1 = Ka * Aa - Cl * C)
dosepoint(Aa)
C=A1/V
error(CEps = 1)
observe(CObs = C + CEps)
stparm(Ka = tvKa * exp(nKa))
stparm(V = tvV * exp(nV))
stparm(Cl = tvCl * exp(nCl))
covariate(wt)
fixef(tvKa = c(, 1.54697,))
fixef(tvV = c(, 0.455465,))
fixef(tvCl = c(, 0.0402979,))
ranef(diag(nV, nKa, nCl)=c(0.01809, 0.41265, 0.06997))
}
------------------------------------
id("xid")
time("time")
dose(Aa<-"dose")
covr(wt<-"wt")
obs(CObs<-"yobs")
table(file=”posthoc.csv”, time(0), Ka,V,Cl)
------------------------------------
Run Options
Method: FOCE L-B
N Iter:1000
Input sorted by subject+time
Enabling automatic log transform (if applicable)
ODE solver method: matrix exponent
Method of computing standard errors: Central Diff
Hessian standard errors
Confidence Level %95
Simple run was performed
This concludes the installation test for Phoenix NLME. Close project without saving it.