Setting up the CDISC Data Preparer object
Right-click Workflow in the Object Browser and select New > Data Management > CDISC Data Preparer.
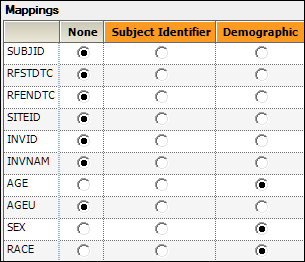
Drag the DM worksheet from the Data folder to the Demographics Mappings panel to map it as the input source.
The columns are automatically mapped to the appropriate contexts:
USUBJID to Subject Identifier.
AGE, SEX, and RACE to Demographic.
These are the columns to include in the output datasets.
Select Exposure in the Setup panel list
Drag the EX worksheet from the Data folder to the Exposure Mappings panel.
There are two mapping sections in the Exposure Mappings. The first section specifies how exposure columns are treated when producing the Dose result dataset. The second section specifies which data columns from the Exposure domain are used to join with the Sample domain and which exposure columns to include in the Sample result dataset.
The columns are automatically mapped to the appropriate contexts:
EXTRT (Name of Actual Treatment),
EXDOSFRM (Dose Form),
EXDOSFRQ (Dosing Frequency per Interval),
EXROUTE (Route of Administration)
to Pivot.
These columns identify unique dose tests as defined in the Exposure tab.
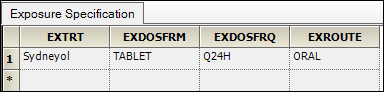
EXDOSE to Dose.
This column contains the actual dose amount.
EXDOSU to Unit.
This column contains the actual unit of the dose amount.
EXSTDY (Study Day of Start of Treatment),
EXENDY (Study Day of End of Treatment),
EXTPT (Planned Time Point Name),
EXTPTREF (Time Point Reference)
to Carry to Dose Dataset.
EXSTDTC (Start Date/Time of Treatment) to Join.
This column will be used to match up data in the PK Findings domain.
EXTRT, EXDOSFRM, EXDOSFRQ, EXROUTE, EXSTDY, EXENDY, EXTPT, EXTPTREF to Carry to Sample Dataset.
This context enables sort keys to be specified between the dose and sample datasets during analysis.
Select PK Findings in the Setup panel list.
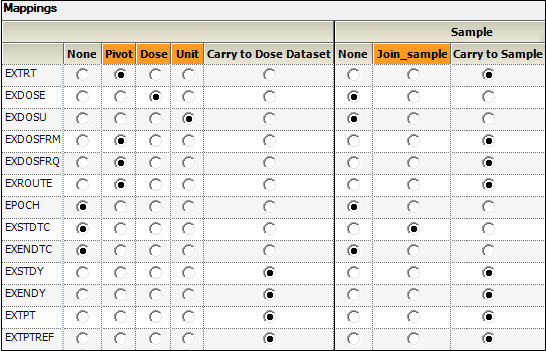
Drag the PC worksheet from the Data folder to the PK Findings Mappings panel.
Most of the columns are automatically mapped to the appropriate contexts.
PCTESTCD (Pharmacokinetic Test Short Name) to Test Identifier.
These columns are used to identify unique PK Findings tests. The unique tests are displayed in the PK Findings (Tests (PC)) tab in the properties.

STUDYID (Study Identifier),
USUBJID (Unique Subject Identifier),
PCSCAT (Test Subcategory),
PCSPEC (Specimen Material Type),
PCSPCCND (Specimen Condition),
VISITNUM (Visit Number),
VISIT (Visit Name),
VISITDY (Planned Study Day of Visit),
PCDTC (Date/Time of Specimen Collection),
PCDY (Actual Study Day of Specimen Collection),
PCTPT (Planned Time Point Name),
PCTPTNUM (Planned Time Point Number),
PCELTM (Planned Elapsed Time from Time Point Ref),
PCTPTREF (Time Point Reference)
to Row.
These are columns to include and represent the unique set of rows. All unique combinations of the Row and Join columns determine the number of sample rows in the result dataset.
Each column selected as a Join column in the EX domain will appear as a column mapping context for the PC domain. This allows specification of the columns in the PC domain that correspond to columns in the EX domain.
PCRFTDTC to EXSTDTC.
Select PK Findings Tests
The PK Findings Tests (PC) tab on the Properties panel is used to select the tests to include, the layout, and the result columns to include in the result sample dataset.
In this example, the dataset only involves one test.
Do not change the default settings for the SYDN PK Findings test, which are.
Usage set to Include to include the test in the output.
Layout set to Stacked to have the results presented in a stacked format.
Result Column set to All to have all results columns included in the output that match the CDISC specification for results columns in original, numeric, or text format.
Continue to the next section.