Prediction and Prediction Variance Corrections
Including a prediction correction and prediction variance correction as part of predictive checking allows observations that would otherwise be incomparable to be pooled together to narrow the quantiles of predicted data, making a more stringent test for possible model misspecification. For example, by using time-after-dose (TAD) as the X axis, data following multiple dose events can be combined. If doses are given at widely varying dose amounts, predictions of plasma concentrations will be proportionally scaled together (assuming a linear model). Similarly, variability correction may apply if, for example, the model is linear but the error model is additive.
Prediction and prediction variance corrections deal with these quantities:
Yij: jth observation for ith subject
PREDij: Population (zero-eta) prediction of jth observation for ith subject
PREDbin: Median of PREDij over all observations in a particular bin
pcYij: Prediction-corrected version of jth observation for ith subject
The prediction-corrected observation is calculated either by the proportional rule (default):
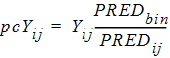
or by the additive rule:
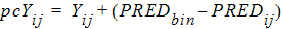
Further, if Pred. Variance is selected, these variables come into play:
sd(pcYij): Standard deviation of pcYij
sd(pcYbin): Median of sd(pcYij) over the bin
pvcYij: Prediction-variability corrected version of Yij
pvcYij is calculated as follows:
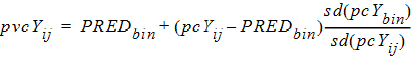
Then either the quantity pvcYij or pcYij is used in the predictive-check plots, depending on whether Pred. Variance is selected.
