The Fixed Effects tab allows users to enter initial, lower bound, and upper bound values for the fixed effects. Every selection made in the Structural tab changes the code for the modified structural parameter. These code changes are displayed in the Model Text tab.
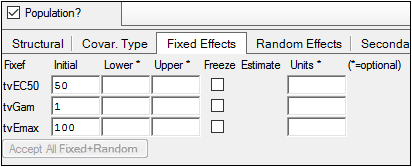
Entering lower and upper bound values for the fixed effects are optional. (See“Using upper and/or lower bounds” below for additional information.)
-
In the Initial field, type an initial value for each fixed effect.
-
In the Lower field, type a lower limit value, if needed.
-
In the Upper field, type an upper limit value, if needed.
-
Check the Freeze checkbox to fix the parameter estimates to the values entered in the initial, lower, and upper fields.
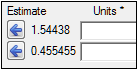
The Estimate area is blank before a model is executed, but will automatically show parameter estimates after the model is successfully executed. Users can choose to accept these estimates as the new initial estimates. (See “Parameters panel” for more information on estimate setup.) -
Click Accept All Fixed+Random to copy all new initial estimates values for all fixed effects, random effects, and the standard deviation.
 The Estimate area only shows the results of the last model run, so when modeling individual subjects, only the estimates of the last subject are displayed.
The Estimate area only shows the results of the last model run, so when modeling individual subjects, only the estimates of the last subject are displayed. -
In the Units field(s), enter the desired unit of measurement for the fixed effect. When executed, the units are applied to the output. If the data has units, the fields are disabled. (See “Units labeling” for more information on handling of units.)
Note that if initial parameter estimates are entered in the Fixed Effects tab, then each sort level model will use the same initial estimates. On the other hand, if the user enters the initial parameter estimates using a worksheet that is mapped to the Parameters panel from the Setup list (either internal or external worksheet), then different initial estimates can be used per sort.
Use the Initial Estimates tab to visually determine a set of parameter estimates that approximate the data. See “Initial Estimates tab”.
Using upper and/or lower bounds
Only use the lower and upper bounds if the model converges on a solution that makes no physical sense, such as a negative rate constant or negative volume. If bounds are entered, the program automatically transforms the parameter to an unbounded space.
For a one-sided bound, a square root transformation is used. For a two-sided bound, a square root transformation is first applied to the original parameter, and then an arcsine transformation is applied to the resulting parameter. To avoid obtaining a negative value, a logarithm transformation is used for the standard deviation of the last residual error, with its lower bound automatically set to be 0.001. This applies to all the engines except for the QRPEM and Naïve-Pooled engines, where the lower bound is set to 0. Moreover, for the QRPEM engine, all bounds are ignored except the embedded lower bound for the last residual error.
It is worth pointing out that all transformations are done internally during the optimization phase and the transformed parameter never appears in any results reported to the user. The internal parameter in unbounded space is always transformed back to the original bounded space before results are reported.
In situations where Multiplicative+Additive residual error models are used or any custom error model involving the standard deviations of some residual errors, there is a possibility of a negative result being obtained for the standard deviation. In such situations, the absolute value of the standard deviation should be considered as the concluding result. To avoid this, the user needs to set a lower bound (e.g., 0) for the parameter.
Phoenix allows the user to label the model parameters (primary as well as secondary) with units. These units do not play a role in the model fitting and no conversion takes place.
When an input dataset has the pertinent columns with units that define units for the model parameters (e.g., for a PK model without covariates: time, concentration and dose), then these units are carried to the output for fixed effects and secondary parameters. In this case, the user is not allowed to enter different units when specifying the model. The units for each column need to be part of the header for Phoenix to understand them as units and carry them forward to the model results. Note that as long as there is text in the unit location, it will be used as unit labels for the fixed effects and secondary parameters. Other Phoenix tools require that the units are valid (as denoted by being between parentheses) to perform unit transformations, but this is not a requirement for Phoenix NLME as these are merely used as labels.
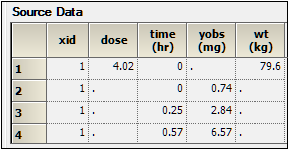
If the input dataset has no column units, then the user can optionally enter the units for each of the fixed effects as well as secondary parameters. These fields do not have any specific requirement as they are used as labels.
There are no requirements for the units as they are used as labels, but it is a good practice for the user to make sure that the units make sense within the dataset (e.g., the concentration mass unit is the same as the dose unit) and that the initial estimates are provided in the expected units. The Data Wizard can be used to do any unit transformation prior to modeling. See the “Data Wizard” description.
It is recommended that the input dataset be consistent with regard to units that define the model parameters. In other words, data values should preferably be in the same mass, time, volume, etc. units.
