Integral has the ability to extract CDISC Data into database tables for use by data mining tools, such as D360™. The domains extracted are limited to the most common domains for SEND and SDTM and for PK analysis (e.g., DM, EX, PC, PP, VS, POOLDEF, and RELREC). Columns extracted are limited to those identified as standard columns in the CDISC implementation guides.
The data extraction is performed by extraction services running on the Integral job server. When a new CDISC dataset is detected, the data is extracted.
The CDISC data extraction contains only the latest revision of each domain. The latest revision is determined by looking for the latest revision date per domain in any folder in the root folder. When a new latest revision is extracted, the previously extracted revision for that domain is deleted.
-
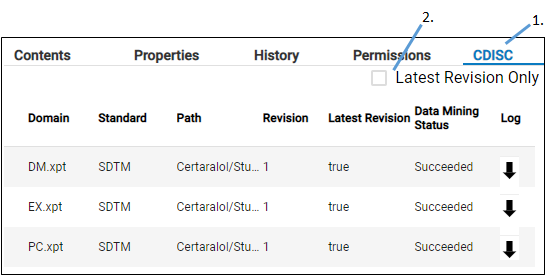
Select a folder and go to the CDISC tab.
-
Use the Latest Revision Only checkbox to list only the most recent version of the domain files.
-
Select a domain file in the Integral browser and go to the CDISC tab
Or
Select a file in the CDISC tab list.
In the CDISC tab, the Data Mining Status shows the status of the data extraction for data mining.
Note that any domain file that does not have a standard specified, will not be extracted. To set the standard, select Edit from the ellipsis menu for the file, then select the standard from the CDISC Model pull-down in the Properties tab.
Clicking the arrow in the Log column downloads the log file generated during file extraction. The extraction log contains:
–information on the number of rows and columns in the XPT file,
–the number of columns extracted and a list of those columns,
–the number of columns not extracted and a list of those columns,
–a list of missing columns that are required according to the standard,
–details for each row and/or cell that has invalid or missing data.
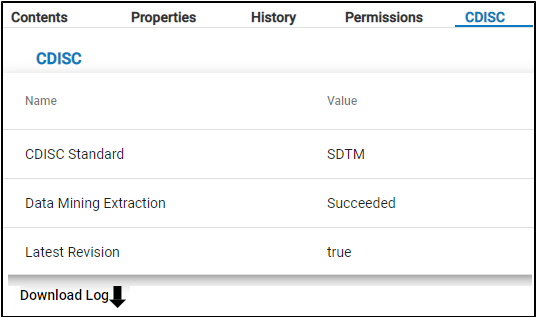
The Download Log button downloads the log file generated during file extraction.
